
For the past 16 months we have worked on analyzing daily ad exchange bid logs with the goal of creating a “signals intelligence” scoring mechanism that could handle 200 billion bid events in a 24 hour cycle with minimal system requirements.
Today we are able to compute the entropy scores for roughly 2 billion rows per 24 hour window on a single regular Linux server with 48GB of memory using a plain vanilla SQL backend.
Nameless is the first ever significant open source contribution for countering ad fraud. It can be effectively adopted by any company and can be complimentary to any other detection method.
What is entropy?
Entropy method is widely used in a variety of prediction challenges, and especially useful with problems where there are many unknowns, such as is the case with the fast moving ad fraud eco-system. Most people have heard
 about entropy in association with thermodynamics, and particularly the Second Law of Thermodynamics, and that is where the concept is coming from. But not everyone know that it was actually entropy method that Alan Turing used when he famously cracked the Nazi Enigma code helping Allies win the World War 2.
about entropy in association with thermodynamics, and particularly the Second Law of Thermodynamics, and that is where the concept is coming from. But not everyone know that it was actually entropy method that Alan Turing used when he famously cracked the Nazi Enigma code helping Allies win the World War 2.
Central to the information age, entropy measurement is simply a measure of randomness (or lack order if you prefer it that way).
For example, the entropy of a line is very low.

On the other hand, if we split the same line in to pieces and disperse it, now we have much higher entropy in the system.

It has been shown by various applications, including NSA and other government mass-surveillance systems, that entropy measurement offers a superior method for unsupervised anomaly detection.
Using Entropy measurement to detect ad fraud
Our premise was very simple; randomness in traffic patterns would tell if a site or app had inventory quality issues. Let’s consider two extreme scenarios:
a) website gets all of its traffic from one IP address
b) website gets all of its visits from unique IP addresses
In the case-a entropy is as low as it can be. In the case-b entropy is as high as it can be.
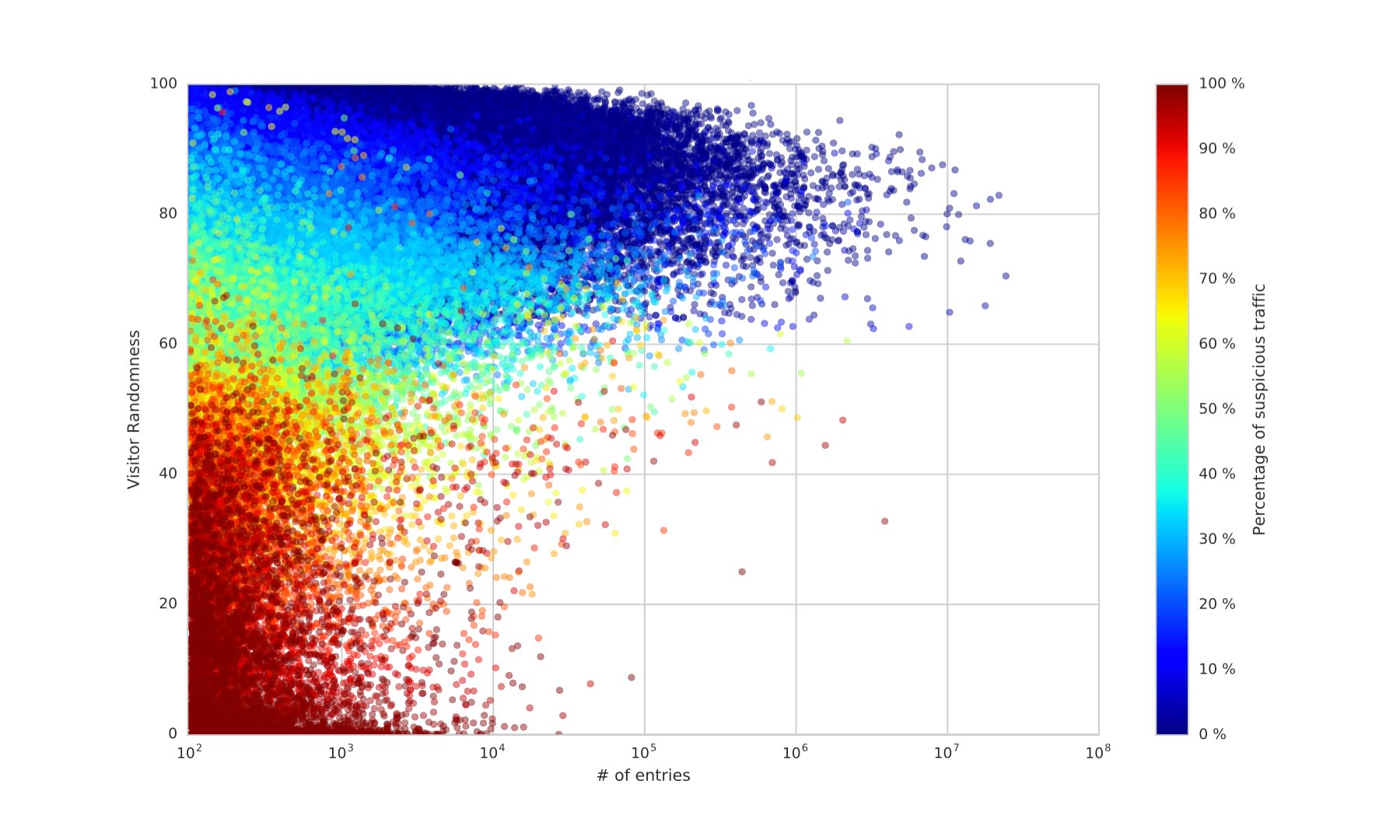
Frankly speaking, if your business is at all dependent on ad inventory quality, the picture does not look too good. In this eco-system advertisers waste a large portion of their money, while legitimate publishers lose their revenues to fraud sites.
Rule based configuration
Nameles gives the owner of the system 100% control over the rule configuration aspect of the system. It can be configured in minutes to settings ranging from spray-and-pray to paranoid. I obviously just made those up, and there are no catchy names but it is really 100% configurable by the user in terms of finding the right balance that meets other business objectives.
Rule based approach allows system owners to easily share rule configurations in a form of a configuration file, if they would choose to do so. For situations where Nameles is deployed as a compliment to an existing detection system or stack, rule configuration allows aligning Nameles with weaknesses or strengths of the propriety system its being used to compliment.